How Parcha Reduces Global AML False Positives by 90% Using Context-Driven LLM Workflows
Parcha's AI assists banks and fintechs drowning in alerts generated from sanctions databases, watchlists, adverse media, and politically exposed persons (PEP) checks.

Last week, we were chatting with the head of compliance at a mid-sized fintech about their AML screening challenges. "We've hit an inflection point," she told us. "Our manual review process just isn't sustainable anymore." This is a conversation we're having more and more frequently with compliance leaders, highlighting a growing crisis in AML that nobody seems to be talking about.
Banks and fintechs are drowning in alerts generated from sanctions databases, watchlists, adverse media, and politically exposed persons (PEP) checks. Each alert needs careful review to keep bad actors off their platform while complying with regulations. It is simple enough in theory, but the scale makes this incredibly challenging in practice.
Let's take a typical peer-to-peer payments company:
- 500 new customers onboard daily with screening required all of them.
- 25% of their 100,000 customer base is re-screened every 90 days to ensure a full annual review.
- 30% of accounts get flagged with adverse media alerts during screening.
- 2–3 adverse media alerts are typically triggered per account —most of which are false positives.
- 10–20 adverse media hits per alert that require manual review.
In practice, this means the compliance team sifts through roughly 5,000 to 10,000 articles every day—amounting to somewhere between 150,000 and 300,000 articles monthly—all before even accounting for extra alerts from transaction monitoring or changes in customer risk profiles.
Additionally, analysts must sift through complex documents spanning multiple formats - news articles, PDFs, and foreign language content - often with interrelated information that requires careful cross-referencing. Traditional automation approaches, like simple text-matching algorithms, have only worsened things. They generate high volumes of false positives that still require expensive human review, effectively shifting the burden rather than reducing it.
We've spent the last year working closely with compliance teams to understand these challenges, and one thing has become crystal clear: throwing more analysts at the problem isn't the answer. The industry urgently needs a more innovative, scalable, and reliable solution to handle the volume and complexity of AML screening.
Challenges in AML Alert Management
Now, imagine scaling this challenge globally. When we work with multinational banks and fintechs, we see how the complexity multiplies. Take something as seemingly simple as screening a customer named "Mohammed Ali" - the alert might pull information from Arabic, French, and English-language sources. Analysts don't just need to overcome language barriers; they need to understand the nuanced context of each document. Is the person mentioned a perpetrator of financial crime, a victim of identity theft, or just someone with a similar name mentioned in passing?
Document formats add another layer of complexity. We regularly see unstructured news articles, scanned PDFs that traditional OCR struggles with, and adverse media reports that vary wildly in format and detail. The conventional approach of using keyword searches or simple text matching isn't just inefficient - it's actively harmful. It floods analysts with false positives, forcing them to spend precious time clearing obvious non-matches while potentially missing genuine risks.

The stakes couldn't be higher. Miss an actual hit, and you risk severe regulatory penalties or reputational damage. Flag too many false positives, and you strain your compliance team while potentially delaying service to legitimate customers.
Our Solution: Intelligent AML Screening
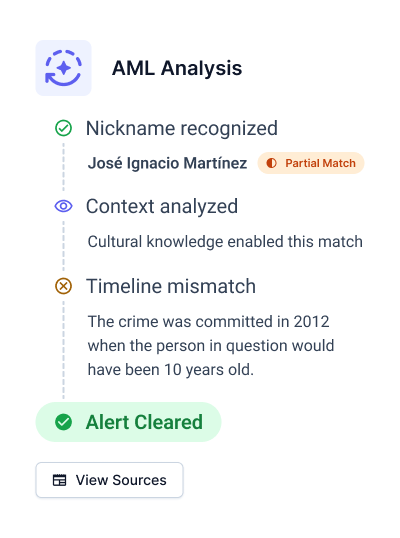
After spending a year deep in the trenches with compliance teams, we've developed a structured, modular approach that directly addresses these challenges. Our solution leverages large language models (LLMs) alongside proven processes to deliver accuracy and efficiency at scale. Let's walk through how this works with a real example.Imagine a customer named "José Ignacio Martínez," a 21-year-old applying for a financial service. During sanctions screening, an alert is triggered for "Nacho Martínez," listed in connection with financial fraud in Latin America. Here's how our system handles this case:
Initial Screening
We start with a smart initial screening layer that combines exact text matching with phonetic algorithms like Soundex and NYSIIS. In this case, while "José Ignacio Martínez" and "Nacho Martínez" share a surname, traditional systems would miss the potential connection between "Ignacio" and "Nacho". Our system flags this for deeper review.
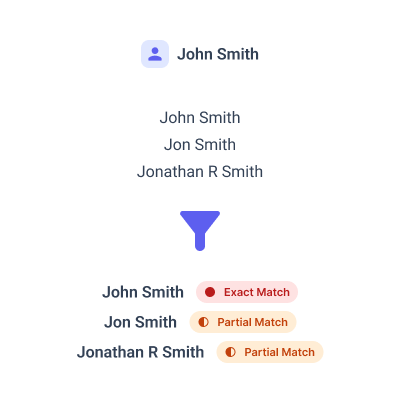
Contextual Name Analysis
Our LLMs analyze names within their cultural and linguistic contexts. In this case, the system recognizes "Nacho" as a common nickname for "Ignacio" in Spanish-speaking cultures, particularly in Mexico. This cultural understanding increases the match probability, triggering further investigation of the alert.
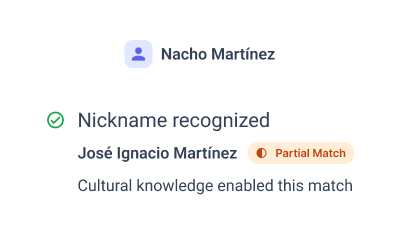
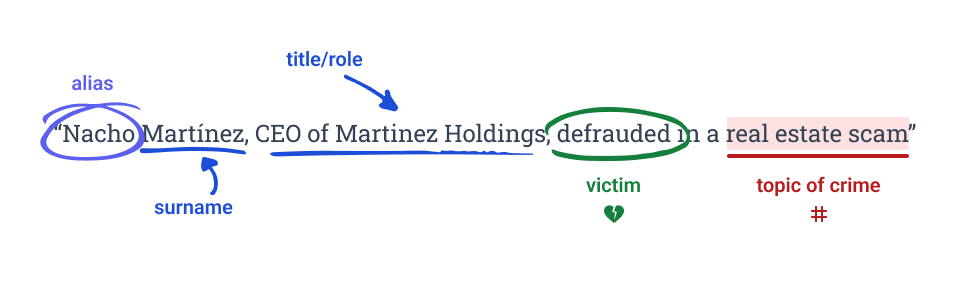
In-Depth Review and Role Identification
The system then analyzes a news article associated with the alert: "Nacho Martínez, CEO of Martinez Holdings, was defrauded in a large-scale investment scam involving real estate projects across Mexico. The scam, which cost the company millions, involved fraudulent contracts presented to Mr. Martínez between 2012 and 2014."
Our LLMs extract crucial contextual details:
- Role: "Nacho Martínez" was the victim, not the perpetrator
- Timeframe: The events occurred between 2012-2014
- Context: The individual was a CEO during this period
- Age Analysis: Our customer, being 21 today, would have been around 10 years old at the time
Final Decision and Audit Trail
Combining this analysis, our system confidently clears the alert without manual review. The detailed audit log documents everything from the initial name matching to the final age-based determination, including:Our LLMs extract crucial contextual details:
- Sources consulted (news article, customer data)
- Cultural nickname analysis
- Timeline evaluation
- Step-by-step reasoning chain
This approach scales across thousands of alerts daily. Whether we're processing clean database entries or messy PDFs, our system maintains this level of thorough analysis while dramatically reducing the manual review burden on compliance teams.
The result? We can clear 90% of alerts automatically while actually improving accuracy. More importantly, analysts can focus their expertise on the complex cases that truly need human judgment rather than getting bogged down in routine reviews.
Challenges with Large-scale Language Models
While large language models (LLMs) provide powerful tools for solving complex problems, relying on them as black boxes introduces significant risks. Systems that lack modularity, traceability, or transparent governance can create unintended consequences. Parcha addresses these challenges by ensuring our workflows are transparent, governed, and designed for operational scale. Below are the key challenges and how Parcha mitigates them:
High Costs of Using LLMs
LLMs often incur significant token-based costs, mainly when applied at scale. For example, screening a million customers every 90 days requires processing millions of alerts, each tied to numerous documents. Without optimization, these operations could result in excessive expenses.
How Parcha Solves This:
- Automated Clearing: Parcha clears 90% of alerts without requiring manual review by leveraging advanced contextual understanding and cultural nuances. The added cost of LLM tokens is more than offset by the reduction of human labor.
- Optimization Platform: Our platform continuously improves accuracy while reducing costs through:
- Automatic prompt revision based on performance data and human valuations
- In-context learning that allows models to adapt to new scenarios without retraining
- Automatic selection of the most cost-effective model for each task
- Model Flexibility: Our portable platform supports multiple LLM types, enabling us to:
- Switch between in-house, foundational, and specialized models
- Fine-tune cheaper models for specific tasks
- Leverage the most cost-effective model for each type of analysis
- Adapt quickly as new, more efficient models become available
- Focused Analysis: Analysts only handle the remaining 10% of alerts, with detailed contextual insights already prepared, reducing the need for repetitive and costly analysis.
Risk of Hallucinations and Obscure Outputs
When approached naively, LLMs can generate results that are either irrelevant or outright hallucinated. For instance, an LLM might create unsupported conclusions or conflate unrelated information in multilingual documents, risking compliance and trust.
How Parcha Solves This:
- Modular Workflows: Each LLM task is designed to solve a specific problem, such as nickname resolution or role identification. This modularity ensures that outputs are controlled and purpose-driven.
- Structured Outputs: We constrain LLM responses to predefined formats and fields rather than allowing free-form generation. For example, role analysis must classify individuals as perpetrators, victims, or witnesses.
- Performance Monitoring: We track critical metrics, including false favorable rates, false negative rates, and consistency scores, to quickly identify any degradation in system performance.
- Human Evaluation: Regular sampling of decisions for human review helps us identify edge cases, improve our prompts, and maintain system reliability over time.
- Traceability: Parcha maintains detailed audit logs for every decision, including sources consulted and the reasoning process. This ensures that outputs are both explainable and verifiable.
- Governance: Strict governance practices are built into our system, allowing organizations to monitor and validate every step of the alert management process.
Conclusion
The complexity of managing AML alerts has grown exponentially as financial institutions face increasing regulatory pressure to ensure bad actors are kept off their platforms. With millions of customers, thousands of daily screenings, and millions of documents to process each month, traditional methods—built on static algorithms and manual reviews—fall short. These approaches fail to scale and result in inefficiencies, high costs, and risks of human error.
Parcha addresses these challenges with a comprehensive, modular solution that combines the power of LLMs with scalable workflows. By automatically clearing 90% of alerts, optimizing costs with efficient models, and providing analysts with rich, contextual insights for the remaining cases, Parcha reduces false positives and streamlines the review process. From initial screening to contextual analysis and audibility, every step is designed to deliver reliable and explainable results.
The value of Parcha’s approach lies in its adaptability. Whether handling multilingual alerts, identifying cultural nicknames, or parsing complex documents, the system scales to meet the unique needs of banks and fintechs operating globally. It avoids the pitfalls of black-box systems by ensuring modularity, traceability, and governance at every stage.
With Parcha, organizations no longer have to choose between compliance, cost efficiency, and operational excellence. They can achieve all three—protecting their platforms, meeting regulatory demands, and improving customer experience.