How our AI models achieve 99% accuracy in production

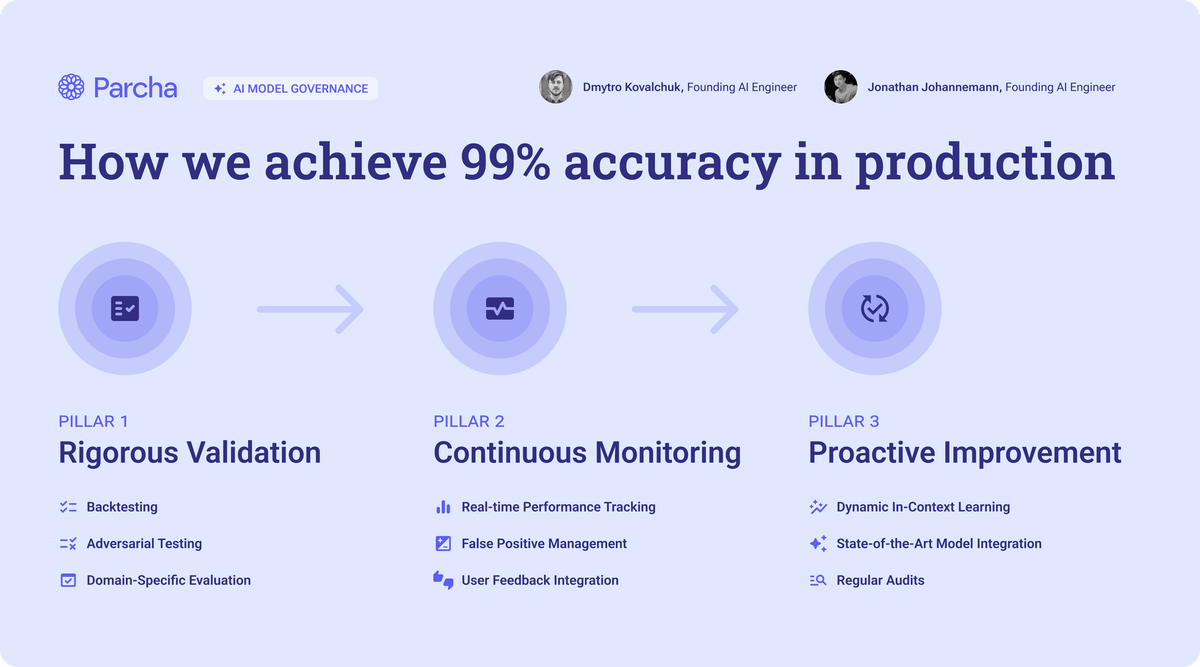
At Parcha, we understand that the effectiveness of our AI-powered compliance solutions hinges on the reliability and accuracy of our AI models. We define an AI model at Parcha to include the underlying LLM as well as the unique prompts we have developed for each specific use case. As we use AI for dozens of different use cases from name matching to document extraction, we have lots of models to validate! That's why we've developed a robust and repeatable framework to ensure our AI models delivers consistent, trustworthy results. We call it the Parcha Model Validation Framework, and it consists of three key pillars:
- Rigorous Validation
- Continuous Monitoring
- Proactive Improvement
Let's dive into each of these pillars and explore how they work together to deliver excellence in AI-powered compliance.
Pillar 1: Rigorous Validation
Before any of our AI models are deployed, they undergo a comprehensive validation process. This includes:
- Backtesting: We use historical client data and carefully crafted synthetic data to simulate real-world scenarios. This allows us to evaluate how our models would have performed in past situations.
- Adversarial Testing: We intentionally challenge our models with edge cases and unexpected inputs using real and synthetic data. This stress-testing helps us identify and address potential vulnerabilities.
- Domain-Specific Evaluation: We tailor our testing to each use case we serve, ensuring our models perform well in the contexts that matter most to our clients. In order to achieve this we generate synthetic data and golden data sets for each compliance check.
This rigorous validation process helps us catch and address potential issues before they can impact our clients' operations.
Pillar 2: Continuous Monitoring
Once a model is deployed, our work is far from over. We keep a constant eye on performance through:
- Real-Time Performance Tracking: We monitor key metrics like precision and recall, ensuring our models maintain high accuracy.
- False Positive Management: We've set an ambitious goal of minimizing false positives. We keep our false positive rate below 10% through careful tuning and vigilant monitoring.
- User Feedback Integration: We actively seek and incorporate feedback from our clients, allowing us to quickly identify and address any issues that arise in real-world use.
This continuous monitoring allows us to maintain 99% accuracy in production and quickly address any deviations from expected results.
Pillar 3: Proactive Improvement
The world of compliance is ever-changing, and our models must evolve to keep pace. We ensure our models stay current through:
- Dynamic In-context Learning: This innovative approach to prompt engineering allows us to continuously optimize our models based on new data and real-world performance using a combination of in-context learning and retrieval augmented generation.
- State-of-the-Art Model Integration: We're always testing and integrating the latest advancements in AI to ensure our models remain at the cutting edge.
- Regular Audits: We conduct both internal and third-party audits to review performance, regulatory compliance, and alignment with business goals.
This proactive approach to improvement ensures our models not only keep up with changes in the compliance landscape but stay ahead of the curve.
Model Validation Framework in Action: AI Name Matching
These three pillars don't operate in isolation – they work together in a continuous cycle of validation, monitoring, and improvement. For example, our continuous monitoring (Pillar 2) might identify a potential issue, which then feeds into our proactive improvement process (Pillar 3). The resulting updates would then go through our rigorous validation process (Pillar 1) before being deployed. This comprehensive, cyclical approach allows us to deliver AI-powered compliance solutions that our clients can trust are 99% accurate in production. With the Parcha Model Validation Framework, we're not just reacting to changes in the compliance landscape – we're anticipating them, ensuring our clients always have the most accurate, reliable, and up-to-date tools at their disposal.
Name matching model
Our AI Name Matching is one of our most frequently used models at Parcha, relevant to any product that evaluates individuals. Name matching at scale is challenging due to cultural variations, transliteration, phonetic similarities, and the list goes on. For example, in Eastern Europe, the name Sasha is often used as a short version of the formal name Alexander. To evaluate our AI Name Matching, we created a synthetic dataset of the most common names across a variety of different countries and cultures. We came up with a list of all of the different ways two names could be a valid match and developed a prompt that would carry out the logic for each type of match. To measure our performance, we evaluated the accuracy of name matches as our primary metric, with others like precision, recall, F1, and F3 as guardrails. This was the work we did as part of Pillar 1 of our framework.
Assessing pilot results
As part of our Pillar 2, while backtesting at the beginning of a recent pilot, we noticed that incorrect name matches were happening more frequently than anticipated. This prompted us to take a deeper look into our evaluation methods and the metrics we collect. As part of this exercise, we decided to break down our accuracy metrics by cultural segments, grouping names by geographical regions. In doing so, we discovered that while the overall metric was quite high, some categories were clearly underperforming, such as Western European names and East Asian names.
Improved Approach using RAG
Our AI engineering team then evaluated several approaches and tuned the model using retrieval augmented generation (RAG), loading few-shot examples into the prompt and allowing the model to learn dynamically in context. This brought the underperforming categories back up to the same level of accuracy as the rest. This experience highlighted the importance of granular analysis and cultural sensitivity in our AI models, ensuring high accuracy across diverse name origins.
Cultural Name Group Analysis - Before & After
Here’s how our name-matching model performed before and after adding dynamic in-context learning.
| Name Group | Initial Accuracy | Final Accuracy | Improvement |
|---|---|---|---|
African | 92% | 100% | 8% |
East Asian | 75% | 93% | 12.35% |
Eastern European | 93% | 100% | 7% |
Latin American | 100% | 100% | 0% |
Middle Eastern | 100% | 100% | 0% |
South Asian | 100% | 100% | 0% |
Southeast Asian | 89% | 100% | 11% |
Western | 97% | 100% | 3% |
Western European | 82% | 97% | 12.46% |
| Overall | 92% | 99% | 6.07% |
The results speak for themselves. Using our model validation framework, we quickly identified an underperforming model and improved accuracy to 99% in production.
Why does model governance matter?
We've seen AI startups claim to have industry-leading accuracy but share very little about how this is measured systematically. As a fintech or bank, it's critical to understand how an AI vendor you're working with develops, monitors, and improves models. Your regulators and auditors will also care about this. Our framework has been developed in partnership with our customers to meet the requirements of publicly traded companies with the highest risk management and governance criteria.
Want to learn more about our model validation approach? Contact Dmytro Kovalchuk on our AI Team.